k3s集群级别日志查询?
当使用 systemd 运行时,日志将在/var/log/syslog中创建,并使用journalctl -u k3s查看。
k3s启动流程
启动api-server
--basic-auth-file=/var/lib/rancher/k3s/server/cred/passwd
--advertise-port=6443
--secure-port=6444
--service-cluster-ip-range=10.43.0.0/16
启动 kube-scheduler 和 kube-controller-manager
启动 kube-proxy 和 kubelet
--eviction-hard=imagefs.available<5%,nodefs.available<5% --eviction-minimum-reclaim=image
fs.available=10%,nodefs.available=10%
启动网络组件flannel
[root@k3s-master ~]# cat /run/flannel/subnet.env
FLANNEL_NETWORK=10.42.0.0/16
FLANNEL_SUBNET=10.42.0.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
6: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default
link/ether 22:c2:a3:e8:c9:c4 brd ff:ff:ff:ff:ff:ff
inet 10.42.0.0/32 scope global flannel.1
valid_lft forever preferred_lft forever
inet6 fe80::20c2:a3ff:fee8:c9c4/64 scope link
valid_lft forever preferred_lft forever
7: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default qlen 1000
link/ether 06:67:a9:94:0f:02 brd ff:ff:ff:ff:ff:ff
inet 10.42.0.1/24 brd 10.42.0.255 scope global cni0
valid_lft forever preferred_lft forever
inet6 fe80::467:a9ff:fe94:f02/64 scope link
10.42.x.x网段:在某些网络插件中,比如Flannel,这个网段可能被用来分配给Pod的IP地址。每个Node上运行的Pod都可以分配到此网段中的一个IP地址。这个网段通常被称为PodCIDR(Pod IP地址段)。
10.43.x.x网段:这个网段可能被用来分配给Service Cluster IP。Service Cluster IP是Service资源的虚拟IP地址,用于负载均衡到后端Pod。这个网段通常被称为ServiceCIDR(Service IP地址段)。
Deleting
# 源IP10.42.0.0/16,目的IP10.42.0.0/16,数据包匹配规则:退出当前链并返回到调用链中的下一个规则
Deleting iptables rule: -s 10.42.0.0/16 -d 10.42.0.0/16 -j RETURN
Deleting iptables rule: -s 10.42.0.0/16 -j ACCEPT
# MASQUERADE用于进行源地址伪装(Source NAT)的目标动作,通常用于NAT(Network Address Translation)规则中,用于隐藏内部网络中的IP地址,使其看起来是外部网络的IP地址。
Deleting iptables rule: -s 10.42.0.0/16 ! -d 224.0.0.0/4 -j MASQUERADE --random-fully
Deleting iptables rule: -d 10.42.0.0/16 -j ACCEPT
Deleting iptables rule: ! -s 10.42.0.0/16 -d 10.42.0.0/24 -j RETURN
Deleting iptables rule: ! -s 10.42.0.0/16 -d 10.42.0.0/16 -j MASQUERADE --random-fully
Adding
Adding iptables rule: -s 10.42.0.0/16 -j ACCEPT
Adding iptables rule: -s 10.42.0.0/16 -d 10.42.0.0/16 -j RETURN
Adding iptables rule: -d 10.42.0.0/16 -j ACCEPT
Adding iptables rule: -s 10.42.0.0/16 ! -d 224.0.0.0/4 -j MASQUERADE --random-fully
Adding iptables rule: ! -s 10.42.0.0/16 -d 10.42.0.0/24 -j RETURN
Adding iptables rule: ! -s 10.42.0.0/16 -d 10.42.0.0/16 -j MASQUERADE --random-fully
k3s-node注册流程
node-passwd:这是与节点名称相关联的密码。它用于节点之间的身份验证和安全通信。当节点加入到 K3s 集群中时,它将使用此密码进行身份验证,并与其他节点和服务器进行通信。
1、启动kubelet等服务,连接到server节点上的api-server服务

server签发证书:k8s组件通信的tls证书,由于那些证书是在server上签发,所以agent需要通过一些API请求获取
node签发证书:由于kubelet在每个节点都运行,所以安全需要我们需要给每个kubelet node都单独签发证书(node-name作为签发依据)。涉及到单独签发就需要验证node信息是否合法
第一步是为了得到启动kubelet服务各种依赖信息;
第二步是为了得到启动kubelet服务各种依赖信息;
第三步是为了得到启动kubelet服务各种依赖信息;
(1)agent先生成一个随机passwd(/etc/rancher/node/password)
(2)把node-name和node-passwd信息作为证书请求的request header发给k3s server,由于agent会向server申请两个kubelet证书,所以会收到两个带有此header的请求。如果agent首次注册,server收到第一个请求后,会把这个node-name和node-passwd解析出来存储到/var/lib/rancher/k3s/server/cred/node-passwd中,收到第二个请求后会读取node-passwd文件与header信息校验,信息不一致则会403拒绝请求。如果agent重复注册时,server会直接比对request header内容和本地信息,信息不一致也会403拒绝请求。
2、建立websocket tunnel,用于k3s的server和agent同步一些信息
注册 k3s 节点失败?
level=error msg="Node password rejected, duplicate hostname or contents of '/etc/rancher/node/password' may not match server node-passwd entry, try enabling a unique node name with the --with-node-id flag"
示例
## master
[root@master ~]# cat /var/lib/rancher/k3s/server/cred/passwd
d4e74c643d76ecfdfb8fc397bbbd383a,node,node,k3s:agent
d4e74c643d76ecfdfb8fc397bbbd383a,server,server,k3s:server
## node1 dev
[root@node1 ~]# cat /etc/rancher/node/password
ffdd8d542334fe20467dcdb79334dd49
## node2 fat
[root@node2 ~]# cat /etc/rancher/node/password
3f2cd7c581084d025f0c9f175af62784
### agent 首次注册,master 节点会把 agent 发送的 node-name 和 node-passwd 解析出来存储到/var/lib/rancher/k3s/server/cred/node-passwd 中
1、检查hostname
2、
跨主机 pod 无法通信?
请参考k3s 网络要求检查主机网络或防火墙,查看 vxlan 对应的 UDP/8472 端口是否开放。
使用 netstat 无法查到 80 和 443 端口?
K3s 使用 traefik 作为默认的 ingress controller。启动之后是通过 iptables 转发 80/443 端口,所以用netstat无法查到对应端口,可以通过iptables,nmap等命令去确认端口是否开启。更多说明请参考k3s 功能扩展之 Helm、Traefik LB、ServiceLB 存储及 RootFS
为什么当一个节点故障时,一个 Pod 需要大于 5 分钟时间才能被重新调度?
这是因为下列默认 Kubernetes 设置共同产生的效果:
kubelet
node-status-update-frequency:设置 kubelet 上报节点信息给 master 的频率。(默认 10s)
kube-controller-manager
node-monitor-period:NodeController 中 NodeStatus 的同步周期(默认 5s)
node-monitor-grace-period:节点被认定为不健康前,节点不作响应的总的时间。(默认 40s)
pod-eviction-timeout:优雅删除故障节点上容器的周期。(默认 5m0s)
获取更多信息请参阅 Kubernetes:kubelet 和 Kubernetes: kube-controller-manager。
在 Kubernetes v1.13 版本中,TaintBasedEvictions特性是默认开启的。请查阅 Kubernetes: Taint based Evictions 获取更多信息。
kube-apiserver (Kubernetes v1.13 版本及以后)
default-not-ready-toleration-seconds: 表示 notReady:NoExecute 容忍的容忍时间。notReady:NoExecute 被默认添加到没有该容忍的所有 Pod。
default-unreachable-toleration-seconds: 表示 unreachable:NoExecute 容忍的容忍时间。unreachable:NoExecute 被默认添加到没有该容忍的所有 Pod。


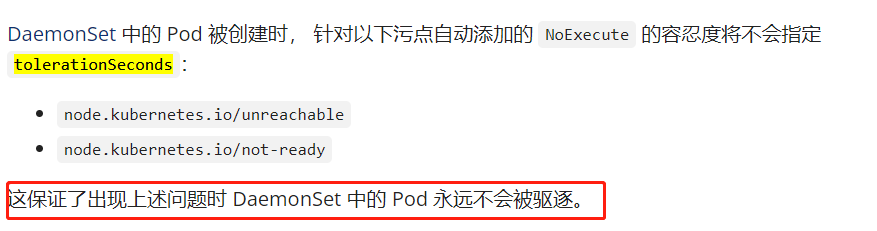
修改办法
kubectl create -f https://raw.githubusercontent.com/kingsd041/rancher-k3s/master/demo-busybox.yaml
K3s worker 节点的角色默认为none,如果修改?
可以通过kubectl label node ${node} node-role.kubernetes.io/worker=worker为节点增加 worker 角色。
Helm-controller使用
1、Helm-controller 运行在master节点并list/watch HelmChart CRD对象
2、CRD onChange时执行Job更新
3、Job Container使用rancher/kilipper-helm为entrypoint
4、Killper-helm内置helm cli,可以安装/升级/删除对应的chart
dns解析异常排查
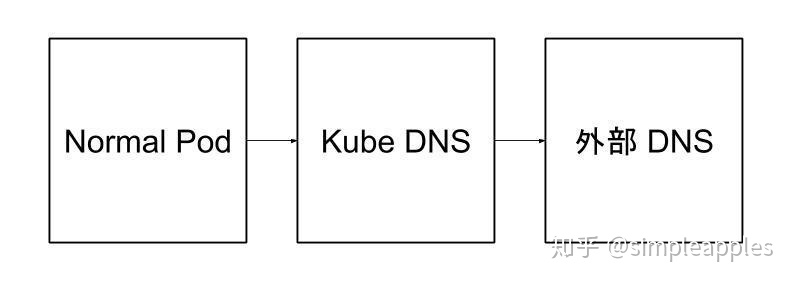
普通 Pod的dnsPolicy属性是默认值ClusterFirst,指向集群内部的DNS服务器;
kube-dns Pod的dnsPolicy值是Default,意思是从所在Node继承DNS服务器,对于无法解析的外部域名,kube-dns会继续向集群外部的dns进行查询
kube-dns Pod的/etc/resolv.conf,集群外部的DNS服务器地址,kube-dns的/etc/resolv.conf文件是从Node中继承来的:
[root@k3s-master ~]# cat /etc/resolv.conf
options timeout:2 attempts:3 rotate single-request-reopen
; generated by /usr/sbin/dhclient-script
nameserver 100.100.2.136
nameserver 100.100.2.138
解析异常
/ # nslookup be-api.default.svc.cluster.local
Server: 10.43.0.10
Address: 10.43.0.10:53
** server can't find be-api.default.svc.cluster.local: NXDOMAIN
*** Can't find be-api.default.svc.cluster.local: No answer
排查
.:53 {
errors
health
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
}
hosts /etc/coredns/NodeHosts {
ttl 60
reload 15s
fallthrough
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
/ # cat /etc/resolv.conf
nameserver 10.43.0.10
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
检查CoreDNS Pod的网络连通性
coredns >> apiserver --通过
telnet <apiserver_clusterip> 6443
telnet 192.168.0.7 6443
coredns >> 主机dns配置的IP或者域名 --通过
运行dig @<upstream_dns_server_ip>,测试CoreDNS Pod到上游DNS服务器的连通性。
其中domain为测试域名,upstream_dns_server_ip为上游DNS服务器地址,默认为100.100.2.136和100.100.2.138。
dig @<upstream_dns_server_ip>
dig kube-dns @100.100.2.136
busybox域名 >> kube_dns_svc_ip --通过
1、执行dig @<kube_dns_svc_ip>命令,测试业务Pod到CoreDNS服务kube-dns解析查询的连通性。
其中为测试域名,<kube_dns_svc_ip>为kube-system命名空间中kube-dns的服务IP。
dig busybox @10.43.0.10
busybox >> coredns_pod_ip --不通过
2、执行ping <coredns_pod_ip>命令,测试业务Pod到CoreDNS容器副本的连通性。
其中<coredns_pod_ip>为kube-system命名空间中CoreDNS Pod的IP。
ping 10.42.0.47
pod域名 >> coredns_pod_ip --不通过
3、执行dig @<coredns_pod_ip>命令,测试业务Pod到CoreDNS容器副本解析查询的连通性。
其中为测试域名,<coredns_pod_ip>为kube-system命名空间中CoreDNS Pod的IP。
dig busybox @10.42.0.47
